這篇文章 會簡單 介紹一下 jieba 這個套件
基本上他的官網就是中文的 大家用起來應該不會有問題
不過我自己有寫
兩個 fun 來做一些應用 講講"模糊比對"和"詞性"
安裝:
我是打 pip3 install jieba 就可以簡單安裝了
講一下簡單的範例
## 大概會用到的幾個套件
import jieba #包含主要的函數
import jieba.posseg #包含詞性的函數
import jieba.analyse #包含抓關鍵字 但我沒用上~
import re #標準表示式的套件
import numpy as np #小白習慣性用的XD
##官方範例~
# jieba.cut 是最基本的切詞方法
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式 # 默认是精确模式
# 他有一個 搜索引擎模式 cut_for_search 但我覺得不好用XD
# 因為它會搜出一大堆字 反而不好處理
# 除非 你之後的處理能更厲害的辨識出哪些是你要的詞
# 不然用 精确模式就好啦
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
# 跑出來的結果~
# 給然 cut_for_search 的 會將類似的字都搜出來 一大堆
![]()
# 另外~ 在 cut 前面加一個 l => lcut
# 他跑出來的就會是一個 list
# 新手小白比較習慣用 list 所以很推薦!!
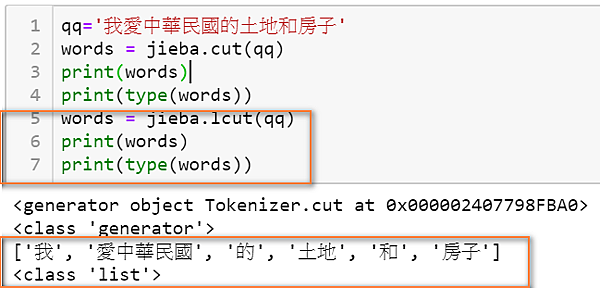
qq='我愛中華民國的土地和房子'
words = jieba.cut(qq)
print(words) ## 出來是 generator
print(type(words))
words = jieba.lcut(qq) ## 出來是 list
print(words)
print(type(words))
## 最後試試 怎麼抓詞性吧
## 使用的就是 jieba.posseg 的套件 一樣有cut 和 lcut
## 不一樣的就是 他會是一個 pairs
words = jieba.posseg.lcut("我爱北京天安门")
for word, flag in words:
print('%s %s' % (word, flag))
## 分別是 切出來的詞 和 詞性
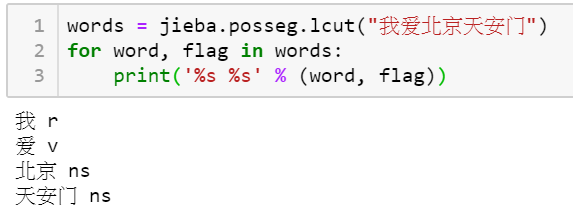
## 你可以看到 r 是主詞 v 是動詞 ns 是名詞
## 他分得蠻細的
## 有興趣可以參考這篇文章 有提到這些代號是甚麼詞
## https://blog.csdn.net/li_31415/article/details/48660073
# 最後看看我的 範例吧~~
# 我這邊練習 寫一個模擬比對的函數
# 然後把一段文字 的名詞抓出來 ( nr ns ... 有 n 的都抓出來 )
# 先建一個比對函數
#------------------------------------------------
## 輸入的 user_input 是一個字串 , collection 則是我要比對的一個字串 list
def fuzzyfinder(user_input, collection):
suggestions = []
pattern = '.*'.join(user_input) # Converts 'djm' to 'd.*j.*m'
regex = re.compile(pattern) # Compiles a regex.
for item in collection:
match = regex.search(item) # Checks if the current item matches the regex.
if match:
suggestions.append(item)
return suggestions
## 輸出的是 list 表示我比對出了那些 字串 (注意喔! 會有重複的)
#------------------------------------------------
##跑跑看
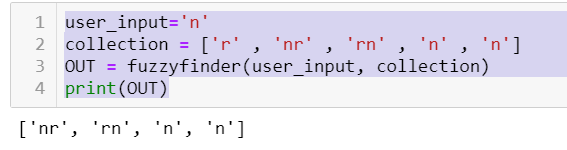
user_input='n'
collection = ['r' , 'nr' , 'rn' , 'n' , 'n']
OUT = fuzzyfinder(user_input, collection)
print(OUT)
### 接下來 利用上面的 function
### 寫出可以抓出 名詞的 function
def words(qq):
seg_list = jieba.lcut(qq, cut_all=False)
print("Default Mode: " + "/ ".join(seg_list))
words = jieba.posseg.lcut(qq)
collection=[]
wordcollection=[]
for word, flag in words:
#print('%s %s' % (word, flag))
wordcollection.append(word) ##字體
collection.append(flag) ##詞性
#### 比對函數 用在這邊
ind=fuzzyfinder('n', collection) ## ind 為主詞的 list 如 ['n','n','nr']
qqq=[]
#### 接下來這段我卡了很久
#### 因為 .index 只會把第一個 遇到 n 的 位置報出來
#### 所以我逼不得已 加了 remove 讓他把遇到的 n 砍掉
#### 砍掉後 我再把 他的位置加 ii 就是每砍幾次加幾次啦~
for ii in np.arange(len(ind)):
qqq.append( int( collection.index(ind[ii]) )+ii ) ## 配合下面的 remove +ii
collection.remove(ind[ii]) ## 每次去掉一個掃過的名詞位置,避免重複抓到同一個位置
#print( qqq )
text=[]
for ii in set(qqq): ##防呆 還是加了unique
text.append(wordcollection[ii])
return text ##最後回傳字串 list
最後 跑個範例吧~~
qq=words('我愛中華民國的土地和房子')
qq

### 看起來很成功喔~~
今天的分享就到這邊啦~~
code 一樣放在這 : http://ge.tt/3h3Ffqp2
檔名是: wordsBloge
新手小白之路 持續進行!!

 留言列表
留言列表


 {{ article.title }}
{{ article.title }}